
Back in early 2023, when AI had just started showing up everywhere, I got handed a problem that sounded simple, let people ask questions in plain language and get a good answer back. Not just any question, though. The answers had to stay inside one specific niche. The niche was a very sensitive one so no wandering off, no making things up, no “as an AI language model” filler.
I said yes before I really knew how I’d do it. Three years and a little over two million answered questions later, I figured it was worth writing down what actually worked. Not the polished version you read in product launches, but the real decisions I made when the tools were brand new and nobody had a playbook yet.
Starting with the obvious problem: the model doesn’t know your stuff
The first thing I learned is that a language model on its own is confidently wrong about anything specific to your world. It has read a lot of the internet, but it has not read your documents. So if you ask it a question about your niche, it will happily invent an answer that sounds right and isn’t.
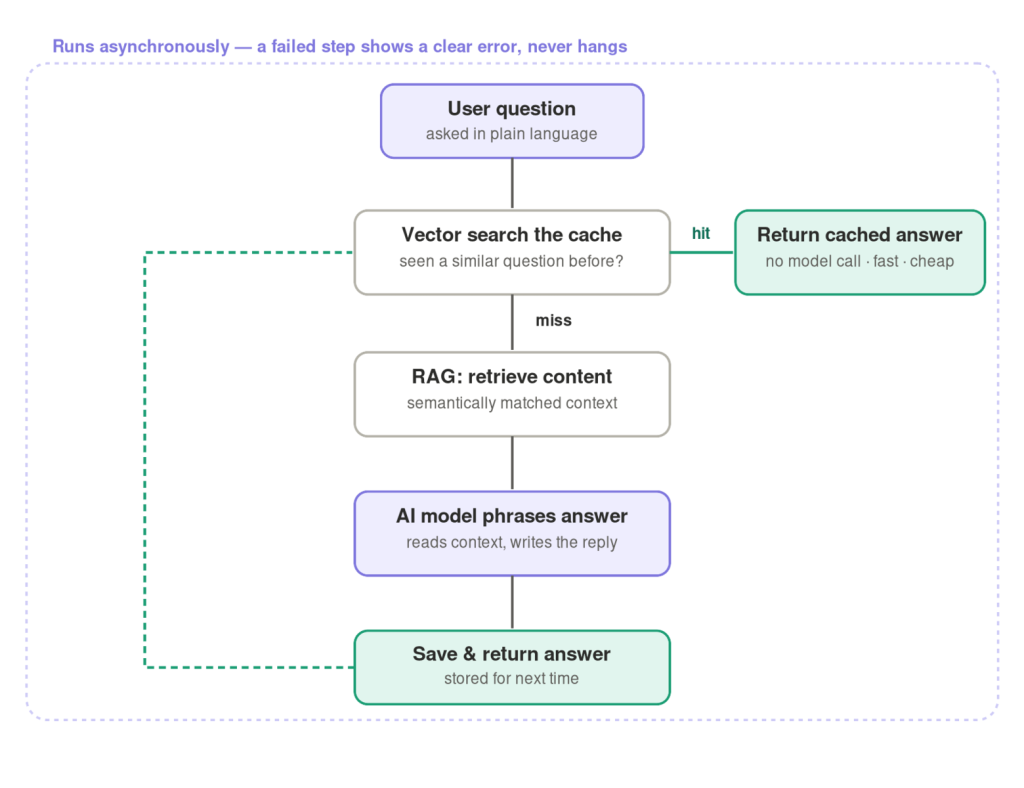
The fix was a RAG system. The idea is plain once you see it: instead of asking the model to answer from memory, I first go find the most relevant pieces of my own content and hand them to the model along with the question. I did this with semantic matching. Rather than searching for exact keywords, the system looks for text that means the same thing as the question, even if the words are different. Someone asking “how do I get my money back” and someone asking “what’s the refund process” both land on the same material. That one change is what kept the answers honest.
Letting the model do what it’s actually good at
Once I had the right context pulled up, the model’s job got much smaller and much safer. It wasn’t being asked to know anything. It was being asked to read the context I gave it and turn that into a clear, friendly answer phrased the right way for the person asking.
That distinction mattered a lot. The retrieval step decides what is true. The model decides how to say it. Keeping those two jobs separate is the single biggest reason the system stayed reliable instead of drifting into nonsense.
The trick that saved a small fortune: answer the question before asking the model
Here’s the part I’m most quietly proud of. Calling a language model costs money on every single question. Two million questions is a lot of single questions.
But people don’t ask two million different things. They ask the same hundred questions in a thousand different ways. So before I ever called the model, I ran the incoming question through a vector search against everything we’d already answered. If someone had asked the same thing before, even in completely different words, I served that answer straight away and skipped the model entirely.
A huge slice of traffic never needed the expensive path at all. It made the whole thing faster and cheaper, which almost never happens at the same time.
Building it so a hiccup doesn’t take everything down
The last lesson came from things breaking, as they always do. Early on, when one piece misbehaved, the whole request would just hang. The user stared at a spinner that never resolved, which is somehow worse than an error.
So I made the system asynchronous. Each step does its work without freezing everything around it, and if a service fails, it fails out loud. The user gets a clear message instead of an endless wait, and the rest of the system keeps serving everyone else. It’s not glamorous work, but it’s the difference between a demo and something people actually trust.
The architecture itself wasn’t particularly complicated. The challenge was deciding where each responsibility belonged. Retrieval found the relevant information, the model turned it into a human-friendly response, and over time I added a shortcut layer that avoided calling the model altogether when we had already answered a similar question before.
What I’d tell someone starting today
The tools are far better now than they were in 2023, but the shape of the solution hasn’t changed much. Ground the model in your own content. Let it phrase, not invent. Cache aggressively, because most questions are repeats. And assume things will break, then build so they break gracefully.
If you got something out of this, a like, comment, or share goes a long way and gives me a nudge to write more. See ya!
Leave a Reply